
Predicting with world models
This week’s article is “World Models” by Ha and Schmidhuber . You can find a fancy interactive version of the article here. To understand this post, you need to have a basic understanding of neural networks, recurrent neural networks / LSTMs and reinforcement learning.
In my own words
Let’s say you want to train a reinforcement learning (RL) agent to solve some task in a complicated environment. All that is given to the agent is the raw image data of its field of view, a set of actions it can take at any time step, and a reward signal.
Ha and Schmidhuber’s approach to this problem is to program separate components for (i) translating the visual input into an abstract representation of the situation, (ii) predicting the future state in terms of that representation, and (iii) choosing actions to take. The third component is intentionally made very simple, so that most of the “work” goes into understanding the environment and the consequences of the agent’s actions.
Incidentally, this setup very much reminds me of my own Rubik’s Cube project, which is why I now blog about this article.
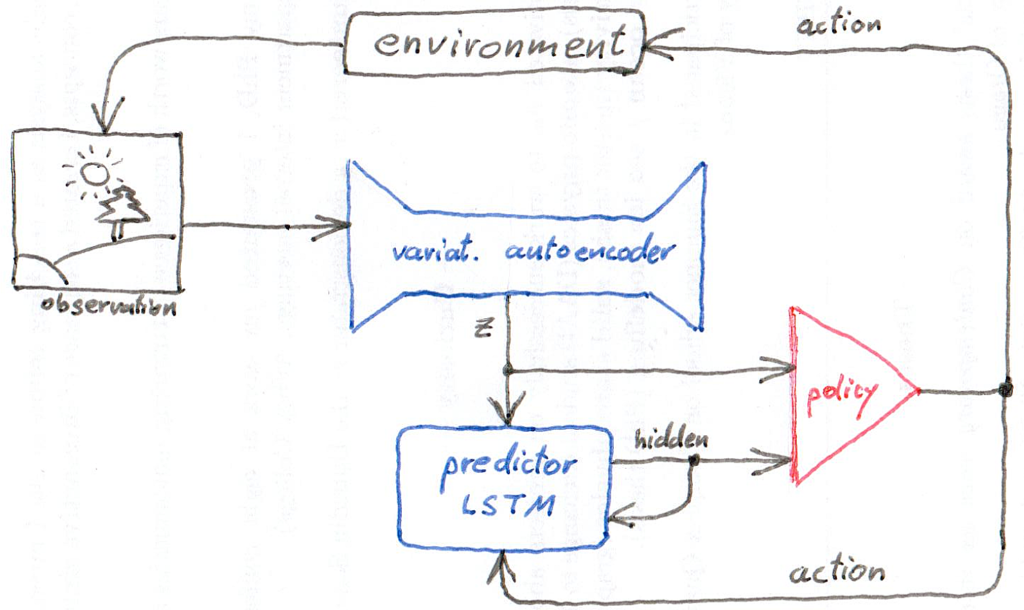
The vision component is a variational autoencoder, which, simply put, is a neural network that takes an image as input and tries to reproduce the same image as output, but is constrained by a hidden layer that has much smaller dimension than the image. Thus, training this autoencoder reproduces an abstract representation z (known as “latent representation”) of the image in the activation of that hidden layer. It is a little bit more complicated than that, but let’s discuss this in another blog post.
The prediction component is a recurrent neural network (RNN). As external inputs, it takes the representation vector z and an action a, and it tries to predict a distribution over possible z vectors in the next time step.
As a recurrent input, the prediction component feeds the state of one of its hidden layers to the next iteration of itself. Thus, it resembles a specific kind of RNN, known as long-short-term-memory (LSTM) network, but what variant of LSTM it is, is not given explicitly in the paper (the appendix contains a reference to another paper, however).
It makes sense to implement the prediction component as LSTM. This allows the network to keep track of information that is relevant for the prediction task over longer periods of time (e.g. “What level of the game am I in?”), and at the same time to selectively pick the information that is relevant at the present moment.
Finally, the policy component is a simple linear unit that takes the state z and the hidden layer from the prediction unit as inputs, and outputs the action to take.
Note, that the policy component does not take the predicted future state distribution as input! Not even a sample of it. Instead it takes the hidden layer of the LSTM. This makes sense, as this hidden layer should convey the relevant information about the present situation. This is a very distinct approach from, say, Monte Carlo tree search over possible futures, and it seems to be more efficient.
Ha and Schmidhuber demonstrate several variations of their setup, as it performs on a simple car racing game and the VizDoom environment, in which the agent has to step left or right to evade oncoming fireballs and stay alive as long as possible.
The fun part is where they let the agent train in a “dream world”. That is, once the agent has trained its vision and prediction components, it can generate scenarios of sequences of future states and even visualize these states using the decoder-part of its vision component (the variational auto encoder).
Thus, the agent can train its policy component without taking actions in the “real” world. This seems particularly useful for training autonomous robots in the actual real world.
As one would expect, the “dreams” are not entirely realistic. Thus, the agent sometimes learns to exploit certain “bugs” in the dream. To counter this, Ha and Schmidhuber introduce a “temperature parameter” which controls the overall uncertainty over the predicted future states. Turning up the temperature makes the dream less predictable, which seems to remedy the exploitation issue.
Opinion, and what I have learned
This article by Ha and Schmidhuber is an interesting summary of a large body of work. The interactive version is especially fun to play with.
Most interesting to me was the idea of feeding the hidden state of the predictor LSTM into the policy component. This might be much more efficient than searching through the space of possible futures, and I can probably use this technique in my Rubik’s Cube project.
It would be interesting to see if one can improve the performance of Ha and Schmidhuber’s framework by replacing the variational auto encoder with a neural process .